
Questo è il primo di una serie di articoli in cui descrivo a grandi linee l’anatomia della mia private cloud, realizzata con materiale di recupero a bassissimo costo e con la poca connettività di cui dispongo. Ovviamente, tengo tutto in garage 🙂
In questa prima parte descriverò il setup hardware e la configurazione di base del sistema operativo, cercando di spiegare il perché di alcune scelte (molto opinabili).
La configurazione di base è composta da 3 server fisici, due identici, uno leggermente differente. Per comodità li chiameremo PVE1, PVE2, PVE3
- CPU
- 4 x Intel(R) Core(TM) i5 CPU 650 @ 3.20GHz (1 Socket) (PVE1 e PVE2)
- 4 x Intel(R) Core(TM) i5-7500 CPU @ 3.40GHz (1 Socket) (PVE3)
- RAM
- 16 GB
- STORAGE
- 1 x 60 GB SSD (sata)
- 2 x 3 TB HDD (sata)
- NETWORK
- 3 x 10/100/1000 Intel Network Card (una integrata, due su scheda PCI dual port)
- OS
- Proxmox VE 6.0
Durante l’installazione, ho scelto di non utilizzare tutto il disco SSD, ma solamente 20GB (ext4), più che sufficienti per Proxmox.
Una volta installato il sistema operativo ho assegnato un indirizzo IP statico alle schede di rete integrate (192.168.1.100, 101 e 102), che verranno utilizzate per il management dei nodi e per il traffico delle VM.
Quindi ho creato un bond per le altre due schede, assegnandogli IP di una classe a parte (10.1.1.1, 2 e 3), perchè verranno utilizzati per il traffico delle repliche e non dovranno poter comunicare con altro che non fra di loro.

Alcune cose degne di nota:
- Bond Mode: in teoria balance-alb permette di fare sia failover, sia bilanciamento di carico completo (in e out). In pratica non mi sembra che il traffico sia bilanciato, grafici alla mano
- Gateway: il bond dedicato alle repliche ne è privo perchè tale traffico non deve uscire da quella sottorete
Purtroppo non avevo a disposizione niente di meglio, l’ideale sarebbe separare il traffico delle VM dalla gestione dei nodi e ridondare tutte le connessioni, quindi se avete macchine adatte (nelle mie proprio non c’è spazio per ulteriori schede PCI), il mio consiglio è 2 schede in bond per il traffico delle VM, 2 schede in bond per il management (eventualmente utilizzabile anche per il backup) e 2 schede in bond per la replica.
Dopo aver configurato la rete, e creato il cluster con i 3 nodi (si veda la documentazione di Proxmox VE), passiamo allo storage.
Lo storage mi ha messo di fronte ad almeno tre problemi: le performance, la gestione e la ridondanza
La prima versione di questa infrastruttura era basata su Gluster FS, ottimo se non ché Proxmox non supportasse da gui la configurazione e non permettesse di effettuare snapshots, neanche per i backup, rendendo i tempi molto lunghi.
Dopo un po’ di prove, sono giunto al seguente setup: ho creato un pool ZFS in stripe (RAID0) con i 2 HDD da 3 TB e ho utilizzato i (circa) 40 GB liberi sul disco SSD come cache per questo pool (chiamato zp1 per comodità).
Questo mi ha garantito performance più che dignitose (la cache fa tanto, è vero, ma non bisogna dimenticare che RAID0 performa estremamente bene parallelizzando l’I/O), per il ferro che c’era sotto.
Mi ha inoltre permesso, ma lo vedremo in seguito, una migliore gestione grazie a ZFS e la sua flessibilità.
Putroppo però, ZFS non è pensato per essere uno shared-fs, quindi sarei rimasto scoperto dal lato della ridondanza. Perfortuna Proxmox prevede un sistema di repliche, andando ad indirizzare il problema della ridondanza.
Una volta che ogni nodo è stato configurato con il suo zp1, è stato sufficiente crearlo a livello di cluster, per fare in modo che ogni nodo vedesse il proprio storage.
A questo punto si incappa in un problema: Proxmox non prevede di conservare su uno storage ZFS altro che Disk image e Container, vale a dire solo i dischi delle macchine virtuali:
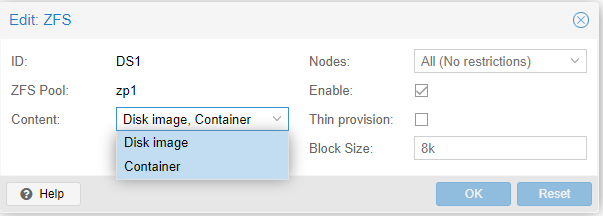
Allora ho creato due storage di tipo directory: FastBackup e Templates, facendoli puntare a due directory residenti su /zp1/, contenti rispettivamente VZDump Backup file e ISO Image, Container Template.
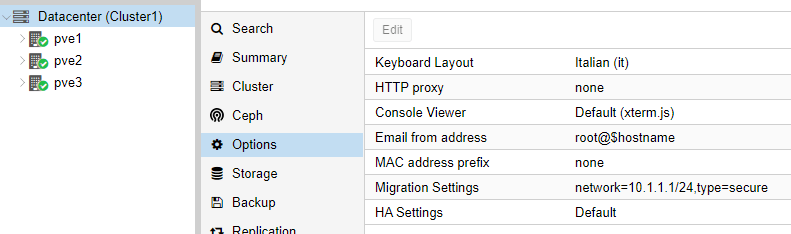
Infine (e questa è una novità di Proxmox VE 6.x), ho modificato a livello di Cluster, Migration Settings per fare in modo che le repliche e le migrazioni delle VM avvengano sulla rete del bond:
Le repliche vanno configurate a mano, per ogni singola VM/LXC, verso ogni nodo. La loro configurazione si trova sia a livello di singolo nodo, sia a livello cluster, alla voce Replication:
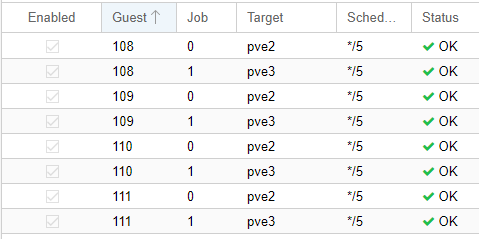
Se vi state chiedendo cosa sia */5 sotto la voce Schedule, ebbene significa ogni 5 minuti. Si, avete letto bene: non spaventatevi, dopo la prima sincronizzazione (che ovviamente richiede tanto tempo quanto è grossa la VM) le altre saranno differenziali (grazie a ZFS e i suoi snapshot!).
Volendo si potrebbero fare anche ogni minuto. Ho un LXC con circa 1 TB di dati che ha sempre replicato correttamente.
A questo punto ci troviamo con il nostro cluster operativo e con le VM replicate sui vari nodi. Per quanto riguarda il backup, si configura a livello di Cluster. Personalmente ho scelto di farlo tutti i giorni, mantenendo uno storico di 5 gg, con compressione GZIP (un po’ più lento ma lo spazio occupato è minore).
Samba configurato banalmente per esportare la share /zp1/FastBackup, mi consente (purtroppo al momento a mano), di salvare su un disco esterno una copia di VM ogni mese. Ho anche un’altra soluzione di backup, ma ne parleremo in un altro articolo.
Alcune note:
– quando un lxc viene migrato, questo viene di fatto spento e riacceso sull’altro nodo e si porta dietro la configurazione della replica, adattandola (quindi se migro il container 100 da PVE1 a PVE2, me lo ritroverò che replica verso PVE1 e PVE3). La migrazione dei container è molto veloce, perchè sfrutta le repliche (snapshot) già esistenti.
– incredibilmente, non ho ancora ben capito perchè, una VM non può essere migrata se sono presenti repliche. Occorre eliminarle e quindi effettuare la migrazione. Il lato positivo è che la migrazione avviene “live”, quello negativo è che impiega molto più tempo di un LXC e poi è necessario ricordarsi di ricreare le repliche. Questo impedisce anche l’utilizzo di HA.
Per il momento è tutto, spero di non aver scritto troppe cavolate… nel caso vi prego di segnalarmele nei commenti qua sotto. Anche se non sono stato chiaro o se ho dimenticato dei “pezzi”, cercherò di rispondere a tutti.
Al prossimo articolo!